


En la Megaclase de Inteligencia ArtificialLa inteligencia artificial (IA) se refiere a la capacidad de las máquinas para realizar tareas que normalmente requieren inteligencia humana. Es un campo fascinante que busca imitar las capacidades humanas para resolver problemas y... Más más grande del país, Freddy Vega (director de Platzi) ofreció la explicación introductoria sobre conceptos básicos de IA. La sesión tuvo lugar el 19 de octubre de 2025, en Parque Tezozómoc, Azcapotzalco. El evento, convocó a niñas, niños, jóvenes y adultos, y buscó establecer fundamentos accesibles para que la ciudadanía comprenda qué es la IA y cómo puede utilizarse. La megaclase fue encabezada por la Jefa de Gobierno Clara Brugada Molina y reunió a autoridades locales y representantes del sector tecnológico.
Megaclase de IA en la CDMX para “democratizar” la tecnología
La Jefa de Gobierno de la Ciudad de México, Clara Brugada Molina, indicó que la megaclase pretende democratizar el acceso y la comprensión de la tecnología para que nadie “se quede atrás”. La administración capitalina impulsa además programas como Mixtli Digital para equipar escuelas primarias y secundarias con tecnología de vanguardia, en línea con la estrategia educativa y tecnológica del evento.
La sesión inicial estuvo dedicada a explicar conceptos básicos de inteligencia artificialLa inteligencia artificial (IA) se refiere a la capacidad de las máquinas para realizar tareas que normalmente requieren inteligencia humana. Es un campo fascinante que busca imitar las capacidades humanas para resolver problemas y... Más, pensados para una audiencia diversa (niñas, niños, jóvenes y adultos). Según el relato del evento, Vega ofreció una introducción conceptual para facilitar la comprensión de la IA entre asistentes sin formación previa.
Freddy Vega: 5 componentes clave de un modelo de lenguaje
¿Te has preguntado alguna vez cómo una máquina puede completar una frase, traducir un texto o mantener una conversación? En los próximos minutos encontrarás una guía clara y directa —sin matemáticas ni de forma complicada— que explica, paso a paso, cómo funcionan los 5 componentes clave de un modelo de lenguaje: tokens, vectores, redes neuronales, atención y RLHF (retroalimentación humana).
Usaremos ejemplos y metáforas cotidianas (diccionario y listas de sinónimos, piezas de rompecabezas) para que lo entiendas rápido y puedas aplicar estas ideas en clases, charlas o decisiones profesionales. Lee con calma, y tendrás una imagen sólida de por qué hoy la IA escribe tan bien; y de cómo tú podrías aprender a construirla.
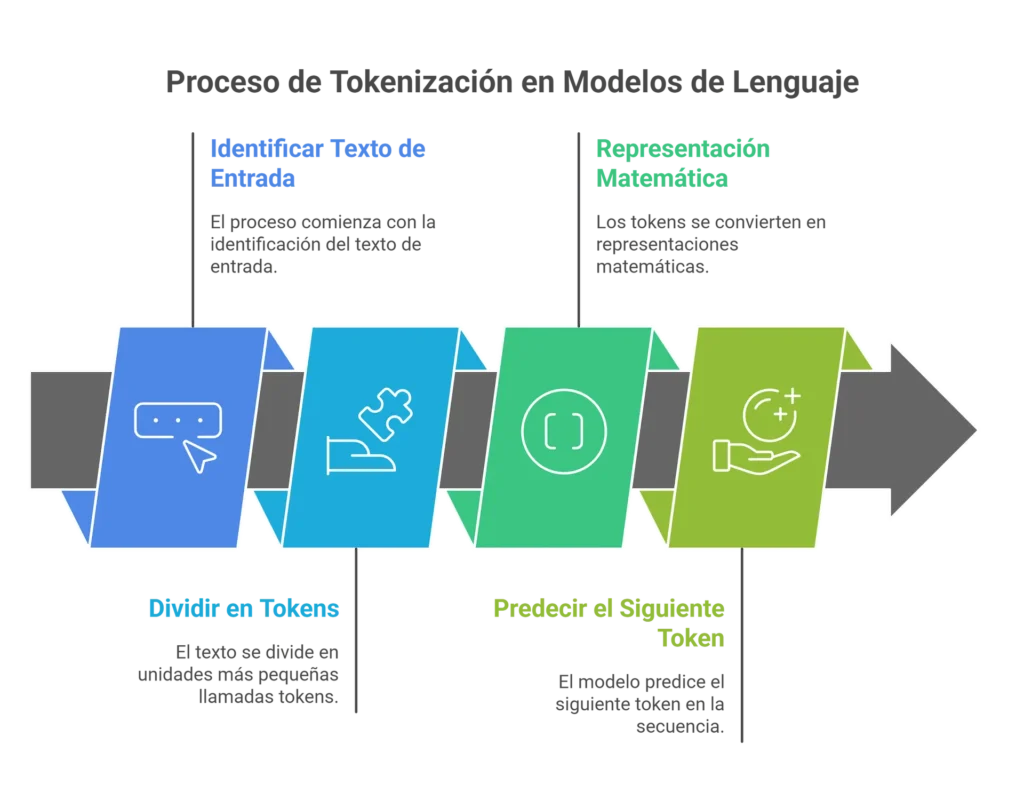
1. Tokens
La tokenización es cortar en pedazos. Imagina que construir una frase es como colocar piezas de un rompecabezas. Cada pieza representa un token. “Los tokens son letras, sílabas o palabras.“, explico Freddy Vega, fundador y CEO de Platzi.
Cuando le das un texto al modelo, lo primero que hace es dividirlo en esos pedacitos (tokenizar). Por ejemplo la palabra “SATISFACCIÓN” puede partirse en tokens como “SAT“, “IS“, “FA“, “ACCIÓN“. Estos tokens son la unidad básica que el modelo usará para representarlas matemáticamente y, luego, intentar predecir la siguiente pieza del rompecabezas.
2. Vectorización (vectores)
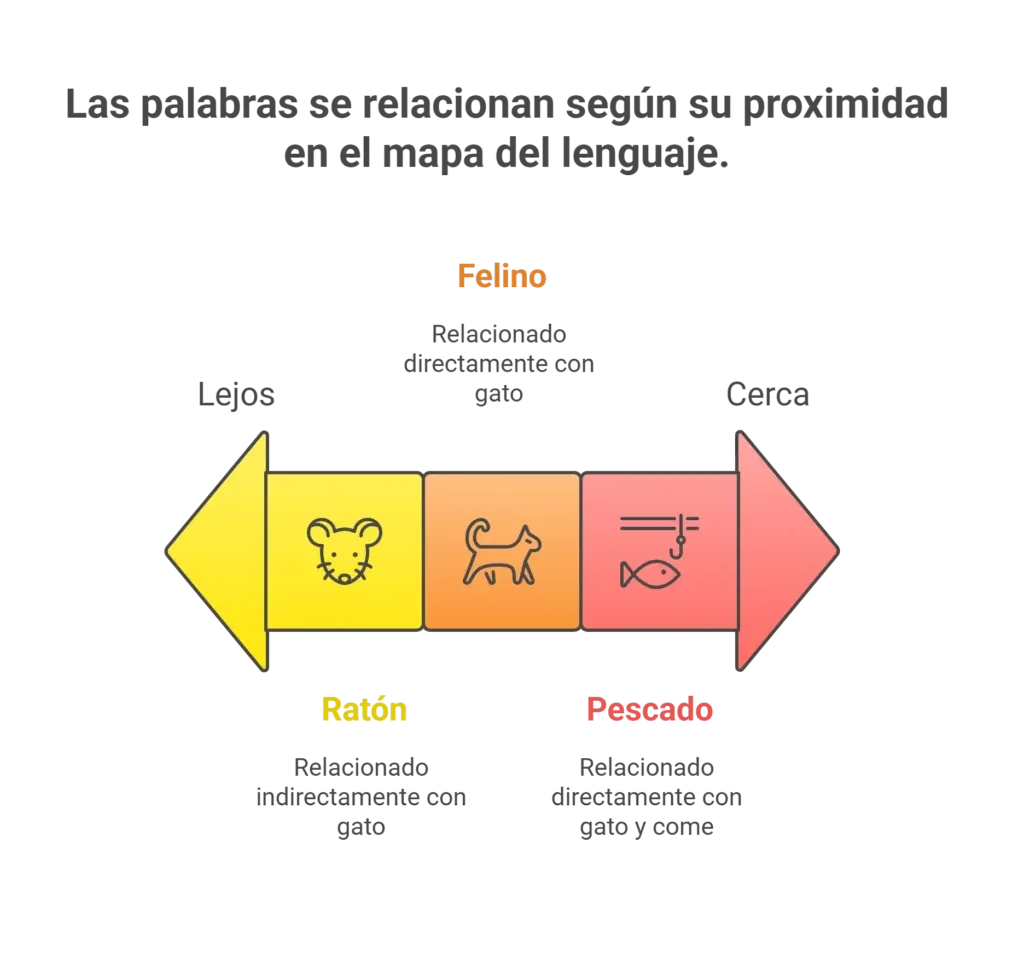
Cada palabra del diccionario tiene, además de su definición, una lista ordenada de sinónimos y palabras relacionadas: esa lista señala hacia otras palabras en el “mapa” del lenguaje. Esa lista ordenada es la forma intuitiva de entender un vector: una señal que muestra qué palabras están “cerca” unas de otras.
Cuando el modelo recibe una frase incompleta, por ejemplo “El gato come ___”, primero ya tiene las palabras que están escritas: “El”, “gato”, “come”. Entonces abre las “listas” correspondientes: la lista de “gato” podría ser “felino, mascota, maullar, ratón, pescado…“, y la lista de “come” podría ser “comida, comer, desayuno, almuerzo, pescado…“.
Para decidir la siguiente palabra, el modelo compara esas listas. Cada vez que una palabra candidata aparece en alguna de las listas suma puntos; si aparece en varias listas suma más puntos. Además, dentro de cada lista las palabras que están arriba (las más cercanas) valen más puntos que las que están abajo. Al sumar todas las pistas, el modelo obtiene una puntuación total para cada candidato y ordena las opciones por esa puntuación. A veces elige la más probable; otras veces introduce un poco de aleatoriedad para variar la respuesta.
En nuestro ejemplo, “pescado” aparece en las dos listas, así que suma muchos puntos y se vuelve una fuerte candidata para completar “El gato come ___“.
No hacen falta fichas infinitas: con un conjunto finito de tokens. Freddy Vega detalla que “entre 100 a 250 mil” para inglés y español, se pueden formar muchísimas frases distintas.
3. Redes neuronales (neuronas)
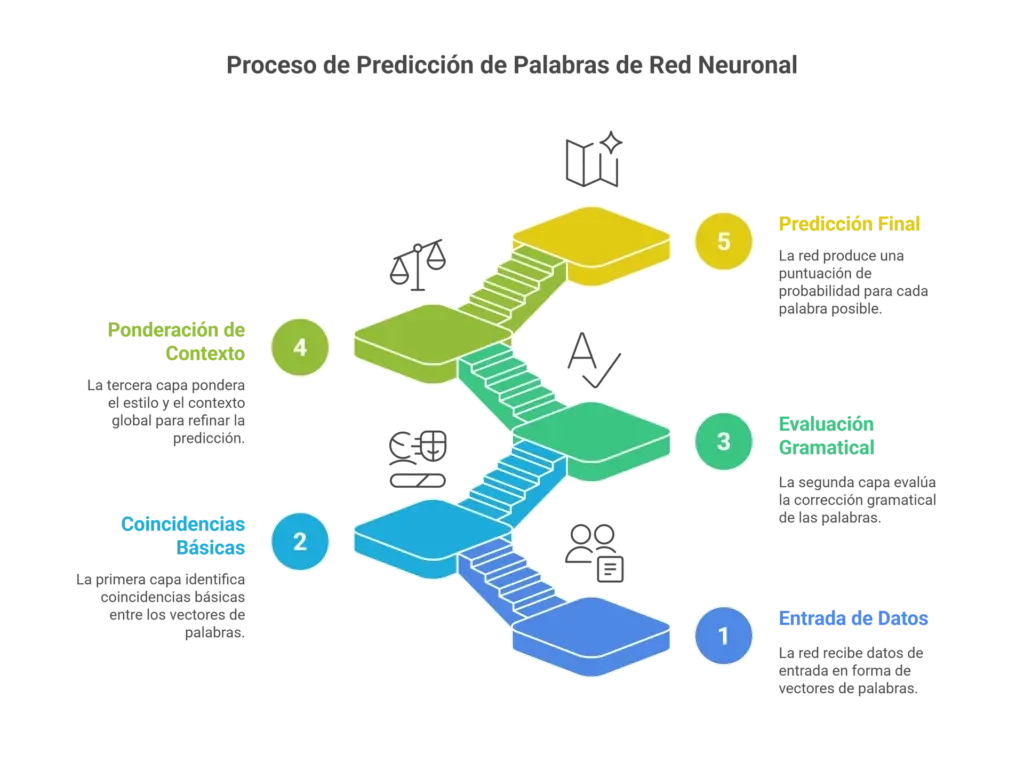
Una red neuronal puede entenderse como una enorme matriz u hoja de cálculo que guarda los patrones del lenguaje en números (pesos). Esos pesos no son ‘palabras’, sino reglas numéricas que indican cómo combinar la información de las listas (vectores) para tomar decisiones.
Cuando el modelo recibe una frase incompleta, ya tiene las listas (vectores) de las palabras del contexto; por ejemplo, “gato” y “come“. Esa información entra al sistema y pasa por varias etapas llamadas capas.
Cada capa actúa como un especialista: aplica las reglas que están guardadas en los pesos y transforma las señales que recibe (las pistas de las listas) en una nueva señal, más refinada. La red no calcula “palabras” directamente en una sola operación; combina muchas señales parciales, capa por capa, y en cada paso las transforma según lo que ha aprendido.
Al final del proceso, la red produce una puntuación o probabilidad para cada palabra posible que podría venir después. Esas puntuaciones se ordenan y sirven para elegir la palabra siguiente (a veces se toma la opción más probable; otras, se elige una alternativa para variar).
Imagina tres expertos (tres capas). El primero detecta coincidencias básicas entre las listas (por ejemplo, que “pescado” aparece en las listas de “gato” y “come“); el segundo evalúa si “pescado” encaja gramáticamente en la frase. El tercero pondera estilo y contexto global para dar la probabilidad final. Esa cadena de decisiones sucesivas es exactamente lo que hacen las distintas capas de la red.
4. Atención (Pregunta, Etiquetas, Valor)
En una partida de dominó no hace falta mirar todas las fichas de todos los jugadores; basta enfocarse en las fichas que importan en la mesa. En los modelos de lenguaje ocurre lo mismo: no procesan cada palabra con la misma intensidad. Se seleccionan las partes del contexto que son más relevantes para decidir la siguiente jugada. “El token más importante siempre es … el último token, el token más reciente del prompt,” mencionó Freddy.
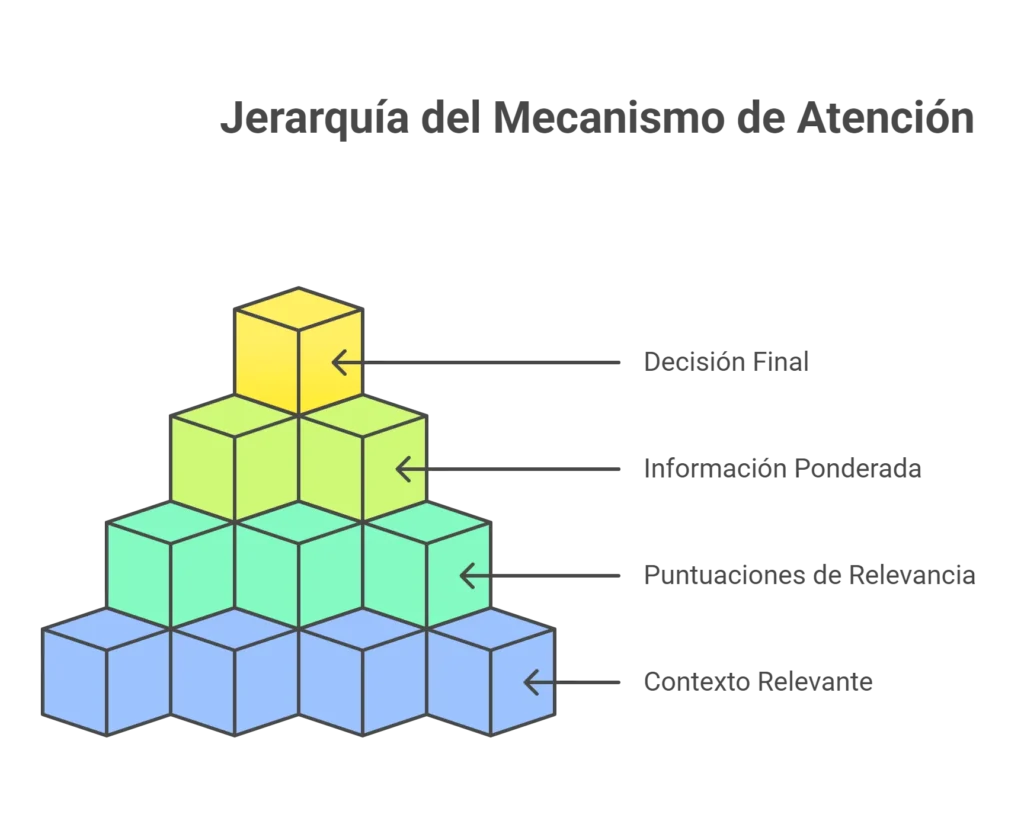
Ese proceso de enfocarse se llama mecanismo de atención. Su función es dar más o menos peso a cada ficha del contexto según cuánto ayude a elegir la próxima ficha. Técnicamente se organiza con tres piezas llamadas Q (query = pregunta), K (key = etiquetas) y V (value = valor), que puedes entender así, sin fórmulas:
- Query (Q, Pregunta): es la pregunta que hace el modelo en este momento; es como mirar la ficha que acabas de poner y preguntarte: ¿qué necesito saber para elegir la siguiente?
- Key (K, Etiquetas): son las etiquetas de cada ficha del contexto; una forma de describir qué contiene cada ficha, como su lista de vecinos o sinónimos.
- Value (V, Valor): es la información real que aporta cada ficha; es el contenido útil que se usará si la ficha resulta relevante.
La atención funciona comparando la pregunta (Q) con las etiquetas (K) de todas las fichas del contexto para calcular una puntuación de relevancia. Esas puntuaciones se usan luego para ponderar (multiplicar) la información real (V) de cada ficha: las fichas con mayor puntuación aportan más a la decisión final. En palabras sencillas: el modelo se pregunta “¿qué fichas del contexto me ayudan ahora?“, evalúa cuáles responden mejor y usa la información de esas fichas para decidir la siguiente jugada.
Por eso la atención hace dos cosas clave:
- Filtrar (no mirar todo por igual).
- Ponderar (dar más peso a lo más útil).
Gracias a ella, el modelo es eficiente (no tiene que considerar todas las palabras) y preciso (se concentra en lo que realmente importa para la frase que está generando).
5. Reforzando lo aprendido con la respuesta humana
Después del entrenamiento inicial, el modelo ya sabe muchas reglas y patrones, pero no siempre responde como queremos en situaciones reales. Aquí entra una etapa extra llamada Reinforcement Learning from Human Feedback (RLHF), que en español podemos llamar “reforzar lo aprendido con retroalimentación humana”.
Esto introduce un ciclo de trabajo de retroalimentación humana. Con la que crea una señal de recompensa usada para ajustar el comportamiento del modelo hacia respuestas preferidas por personas.
¿En qué consiste, explicado fácil?
Imagina que, tras varias partidas, traes árbitros que revisan jugadas y puntúan si fueron buenas o malas. Esos árbitros leen respuestas del modelo y dicen cuáles les gustan más y cuáles menos. Con esas calificaciones humanas se entrena otra vez al modelo (o se ajustan sus reglas): es como pegar etiquetas en la hoja de cálculo (los pesos) para favorecer las jugadas que los árbitros consideran mejores.
¿Por qué es útil?
Antes de RLHF, el sistema solo aprendía a completar texto según estadísticas: generaba continuaciones probables, pero no siempre eran útiles, seguras o bien formuladas para un diálogo humano.
RLHF enseña al modelo a preferir respuestas que los humanos consideran más coherentes, útiles o apropiadas. Gracias a esa “corrección” humana el sistema pasó de ser un mero completador de frases a comportarse mejor como un chat útil.
¿Cómo funciona en la práctica?
- Se generan muchas respuestas del modelo a diversas preguntas.
- Personas (anotadores) clasifican o comparan esas respuestas, indicando cuáles son mejores.
- Esas preferencias se usan para ajustar el modelo mediante un proceso de optimización (reforzamiento) que cambia los pesos para favorecer las respuestas mejor calificadas.
- Se repite el ciclo hasta que el comportamiento del modelo se acerca más a lo que los humanos consideran correcto o útil.
Con RLHF, el modelo aprende no solo a predecir palabras plausibles, sino a priorizar respuestas que las personas prefieren en diálogos reales. Como comenta Freddy Vega: “lo único que hace un modelo de inteligencia artificialLa inteligencia artificial (IA) se refiere a la capacidad de las máquinas para realizar tareas que normalmente requieren inteligencia humana. Es un campo fascinante que busca imitar las capacidades humanas para resolver problemas y... Más moderno es predecir la siguiente palabra. Nada más.” RLHF cambia qué palabras o secuencias el modelo prefiere colocar, alineando esas predicciones con criterios humanos.
Referencias
- Gobierno de la Ciudad de México. (2025, Octubre 19). La Ciudad de México lidera la revolución tecnológica con enfoque humanista, afirma Clara Brugada durante Megaclase de IA. CDMX. https://www.jefaturadegobierno.cdmx.gob.mx/comunicacion/nota/la-ciudad-de-mexico-lidera-la-revolucion-tecnologica-con-enfoque-humanista-afirma-clara-brugada-durante-megaclase-de-ia
